addOutputLoc(partition: Int, status: MapStatus): Unit ShuffleMapStage — Intermediate Shuffle Map Stage in Job
A ShuffleMapStage (aka shuffle map stage, or simply map stage) is an intermediate stage in the execution DAG that produces data for shuffle operation. It is an input for the other following stages in the DAG of stages. That is why it is also called a shuffle dependency’s map side.
|
Tip
|
Read about ShuffleDependency. |
A ShuffleMapStage may contain multiple pipelined operations, e.g. map and filter, before shuffle operation.
|
Caution
|
FIXME: Show the example and the logs + figures |
A ShuffleMapStage can be part of many jobs — refer to the section ShuffleMapStage sharing.
A ShuffleMapStage is a stage with a ShuffleDependency — the shuffle that it is part of and outputLocs and numAvailableOutputs track how many map outputs are ready.
|
Note
|
ShuffleMapStages can also be submitted independently as jobs with DAGScheduler.submitMapStage for Adaptive Query Planning / Adaptive Scheduling.
|
When executed, a ShuffleMapStage saves map output files that can later be fetched by reduce tasks. When all map outputs are available, the ShuffleMapStage is considered available (or ready).
|
Caution
|
FIXME Figure with ShuffleMapStages saving files |
The output locations (outputLocs) of a ShuffleMapStage are the same as used by its ShuffleDependency. Output locations can be missing, i.e. partitions have not been cached or are lost.
A ShuffleMapStage is registered to DAGScheduler that tracks the mapping of shuffles (by their ids from SparkContext) to corresponding ShuffleMapStages that compute them, stored in shuffleToMapStage.
A ShuffleMapStage is created from an input ShuffleDependency and a job’s id (in DAGScheduler#newOrUsedShuffleStage).
|
Caution
|
FIXME Where’s shuffleToMapStage used?
|
-
getShuffleMapStage - see Stage sharing
-
getAncestorShuffleDependencies
When there is no ShuffleMapStage for a shuffle id (of a ShuffleDependency), one is created with the ancestor shuffle dependencies of the RDD (of a ShuffleDependency) that are registered to MapOutputTrackerMaster.
FIXME Where is ShuffleMapStage used?
-
newShuffleMapStage - the proper way to create shuffle map stages (with the additional setup steps)
-
getShuffleMapStage- see Stage sharing
|
Caution
|
|
| Name | Description |
|---|---|
Tracks MapStatuses for each partition. There could be many When The size of |
|
The number of available outputs for the partitions.
|
removeOutputsOnExecutor Method
|
Caution
|
FIXME |
outputLocInMapOutputTrackerFormat Method
|
Caution
|
FIXME |
addActiveJob Method
|
Caution
|
FIXME |
Creating ShuffleMapStage Instance
|
Caution
|
FIXME |
ShuffleMapStage initializes the internal registries and counters.
mapStageJobs Method
|
Caution
|
FIXME |
shuffleDep Property
|
Caution
|
FIXME |
removeActiveJob Method
|
Caution
|
FIXME |
Registering MapStatus For Partition — addOutputLoc Method
addOutputLoc adds the input status to the output locations for the input partition.
addOutputLoc increments _numAvailableOutputs internal counter if the input MapStatus is the first result for the partition.
|
Note
|
addOutputLoc is used when DAGScheduler creates a ShuffleMapStage for a ShuffleDependency and a ActiveJob (and MapOutputTrackerMaster tracks some output locations of the ShuffleDependency) and when ShuffleMapTask has finished.
|
Removing MapStatus For Partition And BlockManager — removeOutputLoc Method
removeOutputLoc(partition: Int, bmAddress: BlockManagerId): UnitremoveOutputLoc removes the MapStatus for the input partition and bmAddress BlockManager from the output locations.
removeOutputLoc decrements _numAvailableOutputs internal counter if the the removed MapStatus was the last result for the partition.
|
Note
|
removeOutputLoc is exclusively used when a Task has failed with FetchFailed exception.
|
Finding Missing Partitions — findMissingPartitions Method
findMissingPartitions(): Seq[Int]|
Note
|
findMissingPartitions is a part of Stage contract that returns the partitions that are missing, i.e. are yet to be computed.
|
Internally, findMissingPartitions uses outputLocs internal registry to find indices with empty lists of MapStatus.
ShuffleMapStage Sharing
A ShuffleMapStage can be shared across multiple jobs, if these jobs reuse the same RDDs.
When a ShuffleMapStage is submitted to DAGScheduler to execute, getShuffleMapStage is called.
scala> val rdd = sc.parallelize(0 to 5).map((_,1)).sortByKey() (1)
scala> rdd.count (2)
scala> rdd.count (3)-
Shuffle at
sortByKey() -
Submits a job with two stages with two being executed
-
Intentionally repeat the last action that submits a new job with two stages with one being shared as already-being-computed
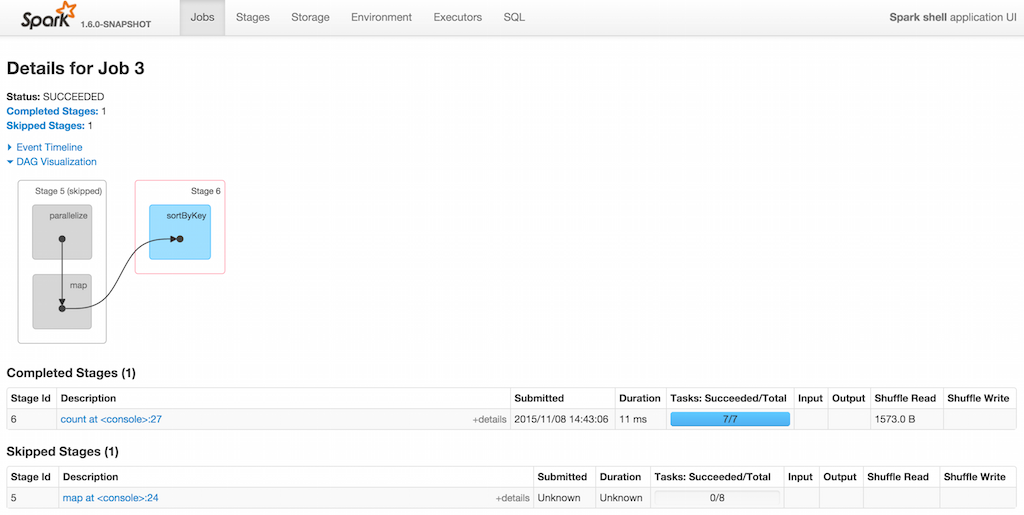
Figure 1. Skipped Stages are already-computed ShuffleMapStages